
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- BatchNormalization
- 정렬
- clibration
- 네이버AI부스트캠프
- 밑바닥부터 시작하는 딥러닝
- Optimizer
- inference
- ImageClassification
- 우선순위큐
- labelsmoothing
- layernormalization
- pytorch
- fasterRCNN
- Focal Loss
- l2penalty
- 중복순열
- cmp_to_key
- DataAugmentation
- 프로그래머스
- 자료구조끝판왕문제
- mmdetectionv3
- 힙
- ComputerVision
- noiserobustness
- autograd
- 네이버 ai 부스트캠프
- labelsmoothingloss
- f1loss
- objectdetection
- focalloss
Archives
- Today
- Total
HealthyAI
Object Detection 본문
반응형

1. Object detection
What is object detection?
- 이미지 내 물체의 위치와 물체의 종류를 맞추는 문제에요.
- Application
- Autonomous driving
- Optical Character Recognition(OCR)
2. Two - Stage Detector
Traditional methods
- HOG = Histogram of Oriented Gradients, SVM = Support Vecor Machine
- 사람 경계선의 평균 - 사람을 찾는데 도움이 돼요.
- 사람의 직관을 통해 알고리즘 설계
- SVM : 선형 분류기
- 관찰할 물체인지 판별하는 도구
- 사람 경계선의 평균 - 사람을 찾는데 도움이 돼요.
- Selective Search
- bounding box 를 추천 해줘요.
- over segmentation - 잘게 쪼개요.
- 비슷한 영역끼리 (색, gradient 특징, 분포) 큰 segmentation로 합쳐요.
- 제일 큰 bounding box를 물체의 후보군으로 선택해요.
R-CNN
- selective search 를 활용해서 region proposal를 input에 맞게 waping 해줘요.
- pretrained 되어있는 CNN 사용 , finetune
- FC layer에서 추출한 feature 만 사용하여 분류는 SVM 방법을 사용하여 분류 하였어요.
- 속도가 굉장히 느리고 학습을 통해 속도 향상이 어려워요.
Fast R-CNN
- 매번 region proposal 한 뒤에 CNN 에 집어 넣어야 하는 과정에서 소요되는 시간의 문제를 해결하고자 하였어요.
- 영상 전체에 대한 feature를 한번에 추출해요. 재활용하여 여러 object 들을 탐지해요.
- Process
- CNN 에서 conv layer 까지 feature map을 뽑아놓아요.
- fully convolution 네트워크는 입력 사이즈에 상관 없다. → 입력 사이즈 waping 안해도돼요.
- Tensor 형태 C, H, W
- ROI Pooling Layer
- 한번 뽑은 feature를 여러번 재활용 하기 위해 제안됐어요.
- ROI : region proposal 이 추천한 물체의 후보 위치들
- ROI 에 해당하는 feature 만을 추출 후 일정 사이즈로 resampling(resize) 해줘요.
- fixed dimension 을 갖기 위해 resampling 진행해요.
- ROI pooling layer = feature pooling
- feature map의 feature들을 추출해요.
- 정확한 위치를 예측하기 위해 bbox regressor를 통해 물체의 위치를 파악해요.
- softmax 를 거쳐 classification 수행해요.
- CNN 에서 conv layer 까지 feature map을 뽑아놓아요.
- 3개의 FC layer 로 각각의 task 를 해결했어요.
- Feature 만 재활용 했는데 R-CNN 대비 18배의 속도 향상을 이뤄냈어요.
- Selective search 와 같은 별도의 알고리즘을 사용하고 있다는 단점이 있어 여전히 end-to-end 구조는 아니에요.
- 데이터 만으로 성능을 높이는데 한계가 있었고 손으로 디자인한 알고리즘의 성능향상 한계를 맛봤어요.
Faster R-CNN
- Selective search - region proposal 과정을 개선하자는 목표하에 진행 됐어요.
- region proposal 과정을 neural network로 대체했어요.
- 최초의 end to end model, 모든 네트워크들이 neural network 형태를 이뤄냈어요. (2015)

- Basic knowledge
- IoU (intersection over Union)
- 두 영역의 교집합 / 두 영역의 합집합 → 클 수록 두 영역이 잘 정합했음을 의미해요.
- Anchor box
- bbox를 예측한 템플릿 형태의 박스들을 미리 정해놓아요. (후보군)
- 가변적인 파라미터 이므로 box 개수는 마음대로 설정해놓아요.
- scale 3개, 비율 3개 → Faster R-CNN 은 총 9개 사용해요.
- loss 를 어떻게 적용할 지의 기준, IoU threshold 0.5라면
- IoU > 0.7 → positive sample (positive loss)
- IoU < 0.3 → negative sample (negative에 대한 loss)
- IoU (intersection over Union)
- Process
- RPN : region proposal network
- selective search 와 같은 third party 대신 제공한 모듈이에요.
- sliding 하면서 매번 k개의 anchor box 고려해요.

- 2k(object or non classification score) cls layer + 4k(x,y,w,h) reg layer
- anchor box 를 엄청 촘촘하게 예상 해놓으면 좋지만, 그렇게 되면 계산 속도가 너무 느려져요.
- 따라서 적당한 양의 k개의 anchor box 를 만들어 놓고 더 정교한 위치는 regression 문제로 풀고자 하는 분할 정복 방식이에요.
- cls → CrossEntropyLoss 사용 2k개 (yes, no)
- Box coordinate reg → regression loss 사용 4k개 (x,y,w,h)
- 전체 타겟 테스크를 위한 ROI 별 카테고리 classification loss 는 따로 존재해요.
- Feature map 을 미리 뽑고,
- RPN → region proposal 여러개 제안
- ROI pooling 수행
- classification, bbox regression 진행
- Non-Maximum Suppression(NMS) 효과적으로 propose 된 region을 필터링 해줘요.(screening)
- RPN 에서 허수로 제안한 박스들을 제거하는 알고리즘이에요.
- 대부분 object detection 에서 표준 적으로 사용됐던 알고리즘, 여전히 사용돼요.
- RPN : region proposal network
- 정리

3. One - Stage Detector
One Stage detector(single) - 정확성을 조금 포기하더라도 속도에 집중하여 real time detection이 가능하게 했어요.
- ROI 관련 내용이 없어요.
- Two stage - region proposal 된 부분에서 sampling 된 위치에서만 classification 선별적으로 진행해요.
YOLO
- input 이미지를 SxS grid로 나눠요.
- bbox, confidence score 를 예측해요.
- class probability map
- k anchor box 와 유사해요.
- 미리 b개의 bbox 정해놔요.
- regression 통해 예측을 확인
- Faster R-CNN 에서 사용한 방법도 사용해요.
- Ground truth 와 매치된 anchor box positive로 간주, 학습 label을 positive로 취해줘요.
- 속면에서는 YOLO 가 가장 빨라요.
- 같은 backbone network를 사용하면 Faster R-CNN 이 정확성 측면에서 앞서요.
SSD
- YOLO는 맨 마지막 layer 에서만 prediction 진행하여 localization 정확성이 떨어졌어요.
- SSD 가 이를 해결해줘요.
4. Two-stage vs One-stage
One stage detectors
- RoI pooling이 없어 모든 부분에서 loss 가 계산돼요.
- 실제 영상에서는 background가 더 크고 실제 물체는 일부분만 차지하고 있어요.
- Detection 문제에서는 이 물체가 적당한 크기의 bbox 로 취급해요.
- 유용한 정보도 없으면서 엄청나게 많은 영역을 차지하여 class imbalance를 발생 시켜요.
- Focal loss

- CrossEntropyLoss 의 확장형이에요.
- Background 예측 값들이 비정상적으로 많은 문제를 해결해줘요.
- Easy example(background) 의 weight 를 줄이고 Hard negative example에 대한 학습에 초점을 맞춰요.
- 감마에 따라서 그래프의 shape 이 결정돼요.
- well-classified examples
- 잘 맞춘 것들은 loss를 낮게 만들고, 잘 못맞춘 것들은 loss를 더 sharp 하게 만들어줘요.
- 같은 x 값에서 r 가 클수록 기울기가 가팔라요.
- 큰 영향을 받게 돼요.
- 정답에 가까운 기울기는 거의 0에 가까워요.
RetinaNet
- Unet 과 매우 유사해요.
- low level의 feature layer 들고 high level feature 들을 잘 활용하면서도 scale 별로 물체를 잘 찾기 위해 이런 구조로 설계했어요.
- 중간 중간 feature들을 addition fusion 시켜요. (Unet 은 concatenate)
- class 의 head와 box head가 따로 구성, classification 과 box regression이 dense 하게 각 위치마다 수행해요.
- YOLOv2, SSD321 보다 속도가 빠르고 성능이 좋아요.
5. Detection with Transformer
- ViT (vision Transformer) by Google
- DeiT (Data-efficient image Transformer) by Facebook
- DETR(Detection Transformer) by Facebook
- transformer 를 object detection에 적용
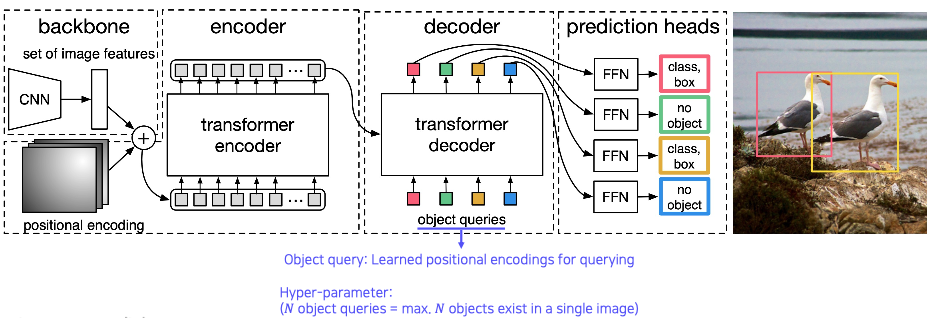
- object query : 학습된 positional encoding
- Transformer 에 질문해요. 이 위치에 해당하는 object가 무엇인지? 질문을 하나씩 넣어줘요.
- 응답을 detection 결과로 사용해요.
- transformer 를 object detection에 적용
- Further
- bbox를 regression 하지 말고 다른 방법이 있는지, 다른 형태의 데이터 구조로 탐지할 수 있는지? 에 대한 연구가 활발히 진행 중이에요.
- 물체의 중심점을 먼저 찾아요.
- 왼쪽 위와 오른쪽 아래를 먼저 탐지하여 효율적인 계산을 취한다 던지 해줘요.
읽어주셔서 감사해요!
반응형