
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- inference
- 네이버 ai 부스트캠프
- 중복순열
- layernormalization
- 밑바닥부터 시작하는 딥러닝
- 우선순위큐
- labelsmoothingloss
- focalloss
- l2penalty
- ComputerVision
- fasterRCNN
- 프로그래머스
- noiserobustness
- BatchNormalization
- autograd
- 힙
- mmdetectionv3
- labelsmoothing
- Focal Loss
- 자료구조끝판왕문제
- Optimizer
- f1loss
- 정렬
- objectdetection
- pytorch
- clibration
- cmp_to_key
- 네이버AI부스트캠프
- ImageClassification
- DataAugmentation
Archives
- Today
- Total
HealthyAI
PyTorch) Dataset & DataLoader 본문
반응형

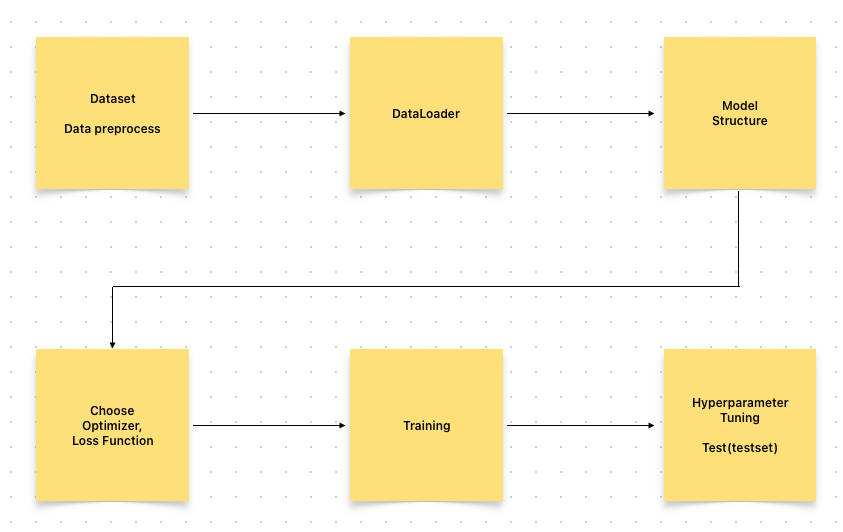
Dataset & DataLoader
Deep Learning Process
- Data - collecting, cleaning, pre processing
- Dataset
- ToTensor(), CenterCrop()
- transforms
- init()
- call()
- transforms
- Dataset
- init()
- len()
- getitem()
- ToTensor(), CenterCrop()
- DataLoader
- batch, shuffle
- Model
Dataset class
- 데이터의 형태를 정의하는 클래스
- 데이터를 입력하는 방식의 표준화
- Image, Text, Audio 등에 따른 다른 입력정의
import torch
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self, text, labels):
self.labels = labels
self.data = text
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
label = self.labels[idx]
text = self.data[idx]
sample = {'Text' : text, 'Class' : label}
return sample- 유의점
- 데이터 형태에 따라 각 함수를 다르게 정의한다
- 학습 시점에 데이터 생성 하면 된다. 모든 것을 데이터 생성 시점에 처리할 필요 없다
- 데이터 셋에 대한 표준화된 처리방법 제공 필요 -> 후속 연구자, 동료 에게 중요
- 최근 표준화된 라이브러리 사용
DataLoader class
- Data의 Batch를 생성해주는 클래스
- 학습직전(GPU feed 전) 데이터의 변환을 책임진다
- Tensor로 변환 + Batch 처리가 메인 업무
- 병렬적인 데이터 전처리 코드의 고민 필요
text = ['Happy', 'Amazing', 'Sad', 'Unhapy', 'Glum']
labels = ['Positive', 'Positive', 'Negative', 'Negative', 'Negative']
MyDataset = CustomDataset(text, labels)
MyDataLoader = DataLoader(MyDataset, batch_size=2, shuffle=True)
next(iter(MyDataLoader))
# {‘Text’: ['Glum', ‘Sad'], 'Class': ['Negative', 'Negative’]}
MyDataLoader = DataLoader(MyDataset, batch_size=2, shuffle=True) for dataset in MyDataLoader:
print(dataset)
Dataset 생성
# {‘Text’: ['Glum', 'Unhappy'], 'Class': ['Negative', 'Negative’]} # {‘Text’: [‘Sad', ‘Amazing'], 'Class': ['Negative', ‘Positive’]} # {‘Text’: [‘happy'], 'Class': [‘Positive']}반응형
'AI > PyTorch' 카테고리의 다른 글
| PyTorch) Model (0) | 2023.03.18 |
|---|---|
| PyTorch) Project (0) | 2023.03.18 |
| PyTorch) AutoGrad, Optimizer (0) | 2023.03.18 |
| PyTorch) PyTorch Basic (0) | 2023.03.18 |
| 밑바닥 부터 시작하는 딥러닝) ch3. 신경망 (0) | 2023.02.01 |
'AI/PyTorch' Related Articles
more


